









As creepy as I find memory in AI tools, I’ve got to admit it makes for a much better experience. After all, that’s why all the major AI labs are directing their efforts so aggressively towards developing personalization and persistent context.
Nobody wants to re-explain their entire project every time they open a new chat. While I’m not a fan of them particularly in chatbots that you use for everyday stuff, I’ve come around to the idea in a coding context. So when I found a way to give Claude Code memory that actually persists and learns across sessions, I had to try it.
Claude Code has two kinds of memory built in
One you write, one that writes itself

Currently, the tool has two memory systems which load at the start of every Claude Code session: CLAUDE.md files and Auto Memory. Both of these systems are complementary, meaning they’re built to work alongside each other rather than as replacements.
The CLAUDE.md is a file that’s stored at the root of your project, and it holds the instructions you write for Claude Code yourself: the conventions, commands, and hard rules you want it to follow every session for that particular project you’re working on. This file is read by Claude Code in full at the start of every session, which makes it the perfect way to hand it everything about the project — essentially anything you’d otherwise catch yourself re-explaining every time. If you’re typing the same correction you typed yesterday, or a code review keeps flagging something Claude Code should already know, that’s exactly the kind of thing that belongs in the file.
While CLAUDE.md files can be auto-generated using the /init command, and you can technically ask Claude Code itself to write one up for you, this file is primarily meant to be written and maintained by you. That’s really the whole point of it. It’s the one part of Claude Code’s memory that’s fully in your hands. Nothing lands in there unless you deliberately put it there, which is exactly why it never sets off the same alarm bells that memory in a regular chatbot does. Rather than automatically picking up information in the background, the file is meant to be home to a set of instructions you deliberately hand over.
This links well to the other half of Claude Code’s memory I mentioned above: Auto Memory. It does exactly what you’d think from the name — instead of waiting for you to write things down, Claude Code takes its own notes as you work, jotting down your corrections and preferences so it doesn’t make the same mistake twice. However, it doesn’t save something every session. It makes a judgment call about whether a given correction or preference is actually worth keeping for next time, and only writes it down if it thinks it’ll be useful later.
Auto Memory is meant to be entirely hands-off. You don’t manage it, you don’t prompt it, and it’s switched on by default (as long as you’re on Claude Code v2.1.59 or later). Like your project’s CLAUDE.md, it’s scoped to whatever you’re working on, which means each project gets its own memory folder, and what Claude Code learns in one doesn’t bleed into the next.
The difference is who’s doing the writing, and what ends up on the page. With CLAUDE.md, it’s you doing the writing, and it’s where all the deliberate stuff goes: your coding standards, your workflows, and the way a project is architected. Auto Memory is for the things Claude Code figures out along the way: the build command that actually works, a debugging insight from a bug you just chased down, or a preference it picked up from watching how you work.
claude-mem gives Claude Code a memory that never forgets
It writes everything down so you don’t have to
The reason why I went down that entire rabbit hole above is to make Claude Code’s native memory system’s shortcomings clear. Auto Memory is selective by design, and there’s no way to go back and search for what it skipped. claude-mem takes the opposite stance: it tries to remember all of it. Its own tagline is “persistent memory compression system built for Claude Code,” and the way it delivers on that is by automatically capturing tool usage observations, generating semantic summaries, and making them available to future sessions. This way, even after you close your terminal and come back, Claude still knows what you were doing.
The mechanism is a chain of lifecycle hooks (which are essentially scripts Claude Code fires at specific moments in a session, so a plugin can hook into what you’re doing without you doing anything). claude-mem wires itself into a handful of them. This includes SessionStart which injects context from your last sessions, UserPromptSubmit saves your prompts, PostToolUse captures an observation every time a tool runs, and the Stop and SessionEnd hooks generate a summary once you’re done. A background worker service takes those raw observations and, as the docs put it, extracts learnings via the Claude Agent SDK, then files everything into a SQLite database with FTS5 full-text search and an optional Chroma vector index for semantic search. In other words, where my native Auto Memory folder is two markdown files, claude-mem is a whole little pipeline running behind Claude Code.
Claude Code works best when you stop asking it to code
Claude Code became far more useful once I stopped treating it like a code generator and started using it to understand projects and terminal chaos.
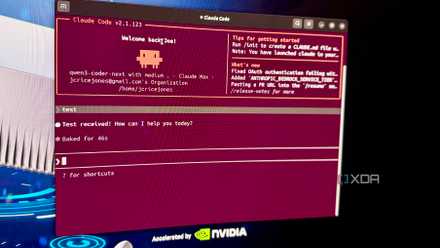
As soon as you install it, the worker spins up a local HTTP service and starts listening for those hooks to send it something. It also serves a web viewer, which is a live stream of everything the tool is deciding to remember, and it updates in real-time as you work. For instance, I ran a session right within a project and asked Claude Code to suggest features to add to it. The stream filled with cards documenting what it had done, including a session summary broken into what it investigated, learned, and completed, alongside separate discovery entries like “Existing Billing model found in codebase” and “Service and controller architecture identified.” Each of the cards is stamped with the project name, a timestamp and a type (eg. discover, feature, session summary) since claude-mem actually goes ahead and sorts what it captures into kinds.
The real test, here, was how Claude worked when I began another session within the same project. Once I did, claude-mem listed what it remembered from the last session before I typed anything. This way, I could quickly catch it up on where we’d left off without re-explaining a thing or rather, I didn’t have to catch it up at all, because it had already caught itself up.

When I gave it a task to do (build a timeline), the summary of that showered it picked up right where the last one ended and built the feature in the codebase’s existing style. For instance, since this was a project for a course I was taking this semester, I preferred using explicit iteration like plain for-loops over anything too clever, since it’s a lot easier to understand. The claude-mem plugin had this preference on record from earlier sessions, and it carried it straight over.
The memory is searchable, and that’s the part that sold me
Ask it what you decided five sessions ago

The automatic recall is the half you notice first, but the half that actually sold me is search. Everything claude-mem captures goes into a searchable database. This means you can walk up to a project weeks later and just ask about it instead of needing to re-read old sessions or scrolling the viewer hunting for a card. You can ask a plain question and get an answer back. Under the hood it’s SQLite full-text search paired with an optional vector index, so it matches on meaning and not only exact keywords, and it’s wired up so that Claude pulls a compact index of hits first and only fetches the full detail for the ones that actually matter, which is how you query months of history without blowing up your context window. But you don’t need to know any of that to use it! There’s a mem-search skill that lets you ask in plain language, so I did.
Several sessions into my hospital project, I typed a simple question about whether I’d ever dealt with billing. The plugin clearly explained that billing had been suggested as a feature twice and that I had picked other work instead. What was interesting here is that this wasn’t something only a single card in the stream mentioned. Instead, it had stitched the answer together from across multiple sessions. It knew billing came up twice, knew which features I’d chosen over it each time, knew a billing module already existed in the codebase from an earlier exploration, and even surfaced a rule I’d mentioned only in passing: that only a patient can pay their own bill, not an admin or doctor.
Claude Code’s real power comes from the tweaks nobody wants to talk about
Claude Code gets better when you stop chasing flashy workflows and start tightening the boring setup details.
Searchable persistent memory is simply something you can’t do with Claude Code’s native memory. Neither of the built-in options are built for it. A CLAUDE.md file is just instructions you write and maintain by hand, so it only knows what you’ve put in it. There’s nothing to search for because it’s not a record of anything, and is simply a set of rules.
On the other hand, Auto Memory keeps a note about how I write and loads it when it’s relevant, but there’s no index behind it and nothing to actually query either. I can’t open a project five sessions later and ask what I’d decided about billing, because neither system is set up to answer that! The claude-mem plugin bridges the gap between the two, and keeps a full record of everything you do within a session, lets you search through it whenever you need to, and also keeps every consequent session aware of the ones before it, so the context builds up over time instead of resetting every time you close the terminal.
Coding memory is memory I can live with
Instead of learning who I am as an individual, the tool is learning how I approach my work. That memory consists of my coding conventions, the commands I actually run, the corrections I keep having to repeat, and the parts of a codebase it should keep its hands off. Some of it is project-specific and some of it follows me everywhere. None of it, however, feels personal the way a chatbot clocking my travel plans does.
With claude-mem, I get exactly the version of that I’m comfortable with: written down where I can see it, kept on my own machine, and searchable when I need it. If there’s something I’d rather it didn’t record, I can wrap it in a private tag and it stays out. That’s the kind of memory I don’t mind handing over, because I can see what it keeps and drop whatever I don’t want!



