










I’m really excited about agentic coding and how AI agents can handle complex tasks while coordinating with one another. The thing is, I always feel like I’m sitting around waiting while the agents work towards their goal, and I want to see what’s going on. Not the hand-waving messages that Claude displays while it’s working, but actually how the decisions were put together.




The question is how to enable this, without being too verbose or not showing enough information. Now, Kanban boards work for my taskflow, but is there such a thing for AI agents to use? It turns out, there are many of them. I started using one called Agency a while ago, but it didn’t fully click for me until I set the tool up to improve itself and read the reports the agentic team made.

That’s the price you need to pay
What is Agency, and why would you use it?
Agents all the way down
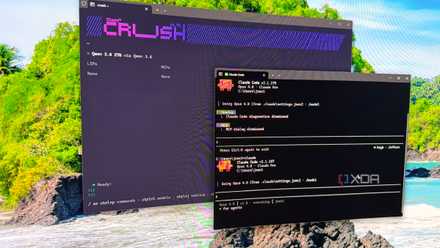
Agency is an open-source FastAPI web app dashboard for running and managing teams of AI coding agents. Phew, that’s a mouthful, but it’s really a simple concept. It functions as an orchestrator for groups of coding agents, working primarily with Claude Code, but you can plug it into Codex, Gemini, Aider, and others. Each project gets its own dashboard and a dedicated team of agents that run on a schedule and track what’s produced.
While you might expect that to be handled in a database, Agency prefers to stay inside a YAML file to define its workflow, and then a tree of markdown files. Everything from proposals, observations, decisions, and agent identities is all in markdown files. That makes it easy for both humans and agents to read, and that’s kind of the whole point.
You install a Group of agents into your project, which has a roster of roles and a dispatch schedule to follow. When agents run on schedule, they record findings as observations, escalate important things into proposals, and then the human element makes the final decision on whether to implement or discard those proposals. It’s all wrapped in a progressive web app (PWA) front-end that’s installable and has a service worker.
What happens when you set AI agents to improve their own software?
Yes, I let Agency agents work on the Agency repo
I was having a few issues getting Agency to run, or, more specifically, keeping it running once it started. So I wondered what would happen if I put an agent group into the Agency repo and let it self-improve. I’d have full visibility because that’s how the tool works, and once it was stable, I could use it on every other project. The default agent team that Agency sets up is a trio:
- Builder/Product: The only agent allowed to edit code, and this implements features, fixes bugs, and keeps the build in the green
- Maintainer: This agent is read-only and monitors security, dependency hygiene, test drift, and runtime health, surfacing problems as they arise
- Strategist: Another read-only agent that tracks the ecosystem, things like upstream API changes, SDK moves, and roadmap gaps, then advises on the next steps
These agents approximate a small development team, but they don’t communicate through API or messages. Everything goes into the filesystem of the Agency dashboard. The Strategist writes an observation; the vital ones are turned into proposals, and then, after human review, those proposals become an approved decision. Decisions then get implemented when the Builder next runs.
It’s an auditable, asynchronous process, so my system doesn’t get bogged down by shared memory needs. And because I have to approve any changes, the potential for damage is one commit to roll back, instead of however many changes the normal Claude Code agentic workflow allows.
Two things surprised me. The amount of mergeable work produced because every piece of code change was planned and decided on beforehand. And that every failure of the system was due to the system, and not the fault of the agents.
I run a 24GB GPU instead of paying for Claude or Codex, and Qwen 3.6 keeps up more than I expected
Local LLMs are good enough for many tasks
The agents didn’t always get things right
But a few fixes later they were working as expected

LLMs are only as good as the surrounding tooling, and this project gave me ample evidence to support that. Every failure mode looked successful from where I was sitting, and without the markdown files to drill into, I wouldn’t have known.
The dashboard was filling up with observations and proposals, and I’d approved the ones I wanted actioned. Or I thought I had, but a few days later I noticed nothing was being built. The issue was a misconfigurationin which the tool was returning decisions to the read-only agent who raised the issue, rather than to the Builder persona, which could create new code.
The dispatch logic in the original Agency repo was designed as shell scripts, which silently failed on my Windows system. The time zone setting was ignored. Dry runs fired as actual runs because the logic was discarded, and the tooling it needed was in different paths under WSL compared with Git Bash. I could have fixed the individual issues, but instead I rewrote things to a cross-platform runner.
Once that was done, I set up Agency groups in two more repos and let them run for a few days. One of the groups stopped working after the first dispatch, but the dashboard remained green, and the dispatch script kept running. And it was the script that was at fault: it processed groups sequentially, and the last group tried to run after the 15-minute window the script allowed. A good lesson in scheduling issues in code, and something I won’t forget in a hurry.
My favorite Claude prompt is ‘write me a better prompt’ — and it saves hours every week
The simple workflow saves me hours weekly
Seeing all the decisions my agents make gives me a new appreciation for what’s going on
One of the things I don’t like about agentic coding is that often the failure mode is silence. That could be a group not managing to read the data it needs, or a proposal that was approved but not actioned, or a server that disconnects when the terminal window running it gets accidentally closed. Having Agency running and doing self-improvement shows me what’s going on while adding an important layer of reliability around the agentic harness. And even when the dashboard failed, I could still see what was happening because all the data was in markdown files.

